
#
Confidential Computing
Many cloud providers rely on operational assurance — policies and administrative controls — to protect customer data. Phoeniqs takes a different approach: technical assurance through cryptographic and hardware-enforced controls that make access to plaintext data technically infeasible, even for our own administrators.
Our philosophy is to protect data across its entire lifecycle: in transit, at rest, and in use.
#
Operational vs. Technical Assurance
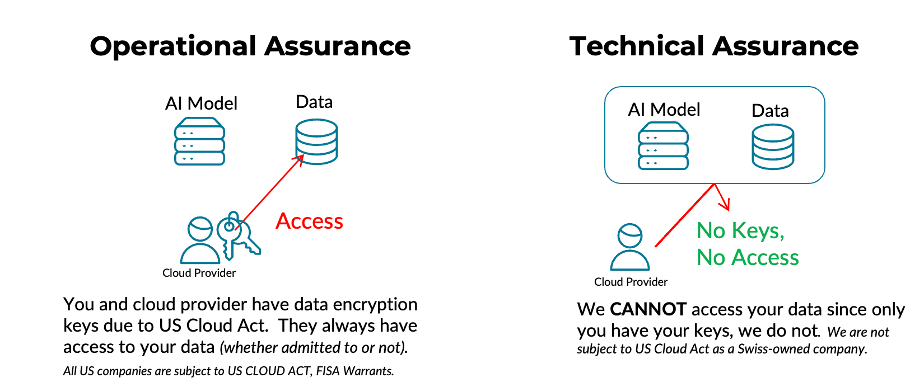
Why this matters
- CLOUD Act exposure: Hyperscalers subject to the U.S. CLOUD Act may be compelled to provide data. Phoeniqs is not a U.S. provider and implements a zero-access architecture — we do not possess customer keys.
- Zero-access Operations: Even if compelled, we are technically unable to decrypt customer content.
- Auditability: Hardware attestation proves that only verified code runs before any secrets are released.
#
Confidential Containers (CoCo) for AI
Confidential Containers (CoCo) leverage trusted execution environments (TEEs) to isolate sensitive workloads from the host OS, other tenants, and the cloud provider.
To address confidential AI, IBM Research has proposed a robust architecture for protecting LLM inference workflows end-to-end:
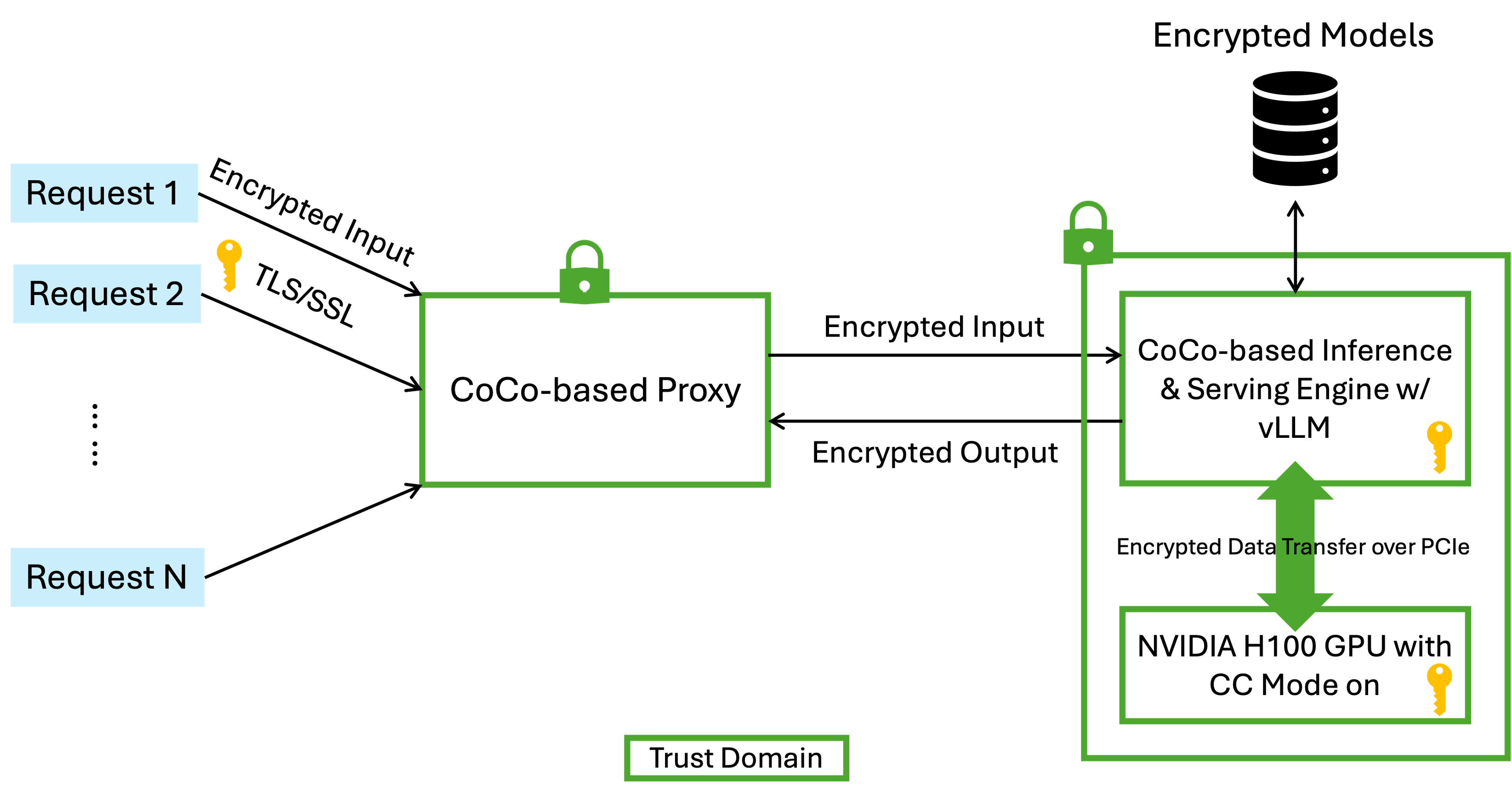
#
Confidential AI for Model as a Service
Phoeniqs extends confidential computing to GPU workloads — ensuring prompts, model weights, and inference data remain encrypted and isolated during execution, using IBM LinuxONE, Hyper Protect virtualization, and OpenShift AI.
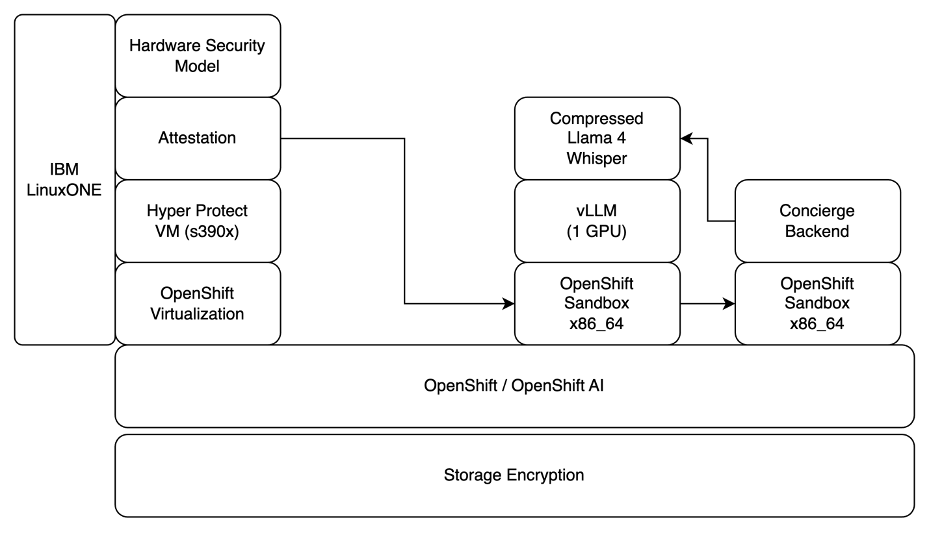
Zero-access guarantee
User prompts, model weights, and runtime memory execute inside confidential computing enclaves with attestation — even privileged admins cannot access plaintext workloads.
#
Architecture & Data Flow
#
1. Client encrypts and sends request
Client encrypts the request and sends it via TLS to the AI Gateway enclave.
#
2. Request is processed inside the enclave
The request is decrypted inside the enclave, policy-checked, and re-encrypted for the Model Serving enclave.
#
3. Model executes and returns output
The model executes inside the enclave. Output is re-encrypted and returned to the client.
#
4. Minimal metadata stored
Only minimal metadata leaves enclaves, stored per the Data Processing Agreement (DPA).
#
Security Summary
#
Phoeniqs vs. Hyperscalers
#
Notes
Compliance & Documentation
These commitments align with our published Data Processing Agreement (DPA) and Data Privacy Policy available on phoeniqs.com.
tip Need help?
If you experience any issues or need assistance, please contact support.